
Via quantization LLMs can run faster and on smaller hardware. This post describes how to run Mistral 7b on an older MacBook Pro without GPU.
Llama.cpp is an inference stack implemented in C/C++ to run modern Large Language Model architectures. GGUF is a quantization format which can be run with llama.cpp.
Here is some background information:
- Quantization
- llama.cpp
- Mistral-7B-Instruct-v0.2
- Mistral-7B-Instruct-v0.2-GGUF
- How is LLaMa.cpp possible?
Setup
To set up llama.cpp, follow the instructions in the readme.
1
2
3
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
make
If you want to access the models via Python, install llama-cpp-python.
1
2
3
4
python3 -m pip install --user virtualenv
python3 -m venv venv
source venv/bin/activate
python3 -m pip install llama-cpp-python
Download Model
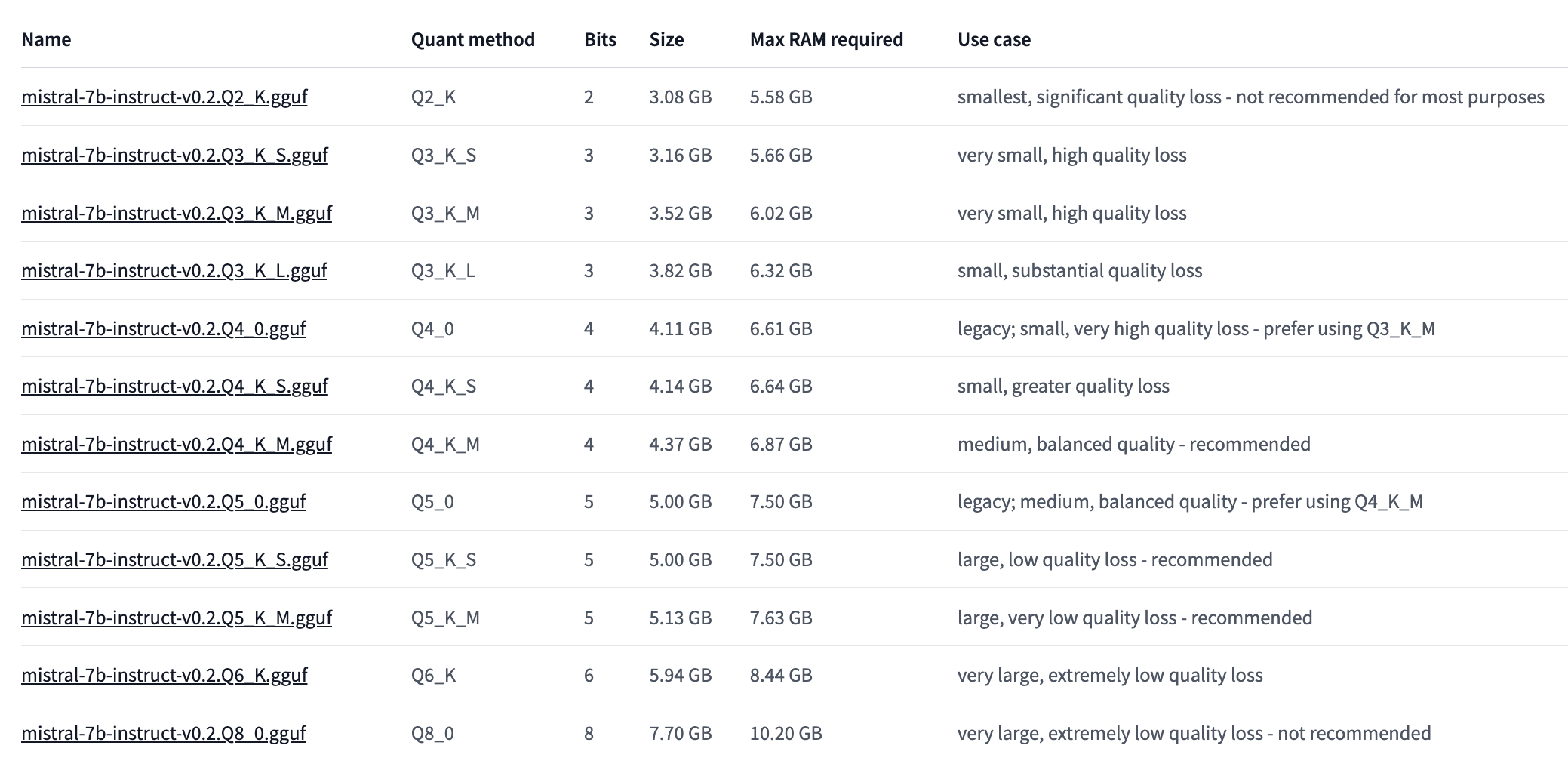
While you can quanitze models yourself, for a lot of popular models there are already GGUF versions on HuggingFace. In the example below I use Mistral 7b which exists in different variations.
Run Model
To run the model on a CPU only, it is important to set “-ngl 0”.
1
2
3
./main -m ./models/mistral-7b-instruct-v0.2.Q6_K.gguf \
-ngl 0
-p 'Who is the president of USA?'
You can also put the prompt in a file.
1
2
3
4
./main -m ./models/mistral-7b-instruct-v0.2.Q6_K.gguf \
-ngl 0 \
-f ./prompts/my-prompt.txt \
--temp 0.0
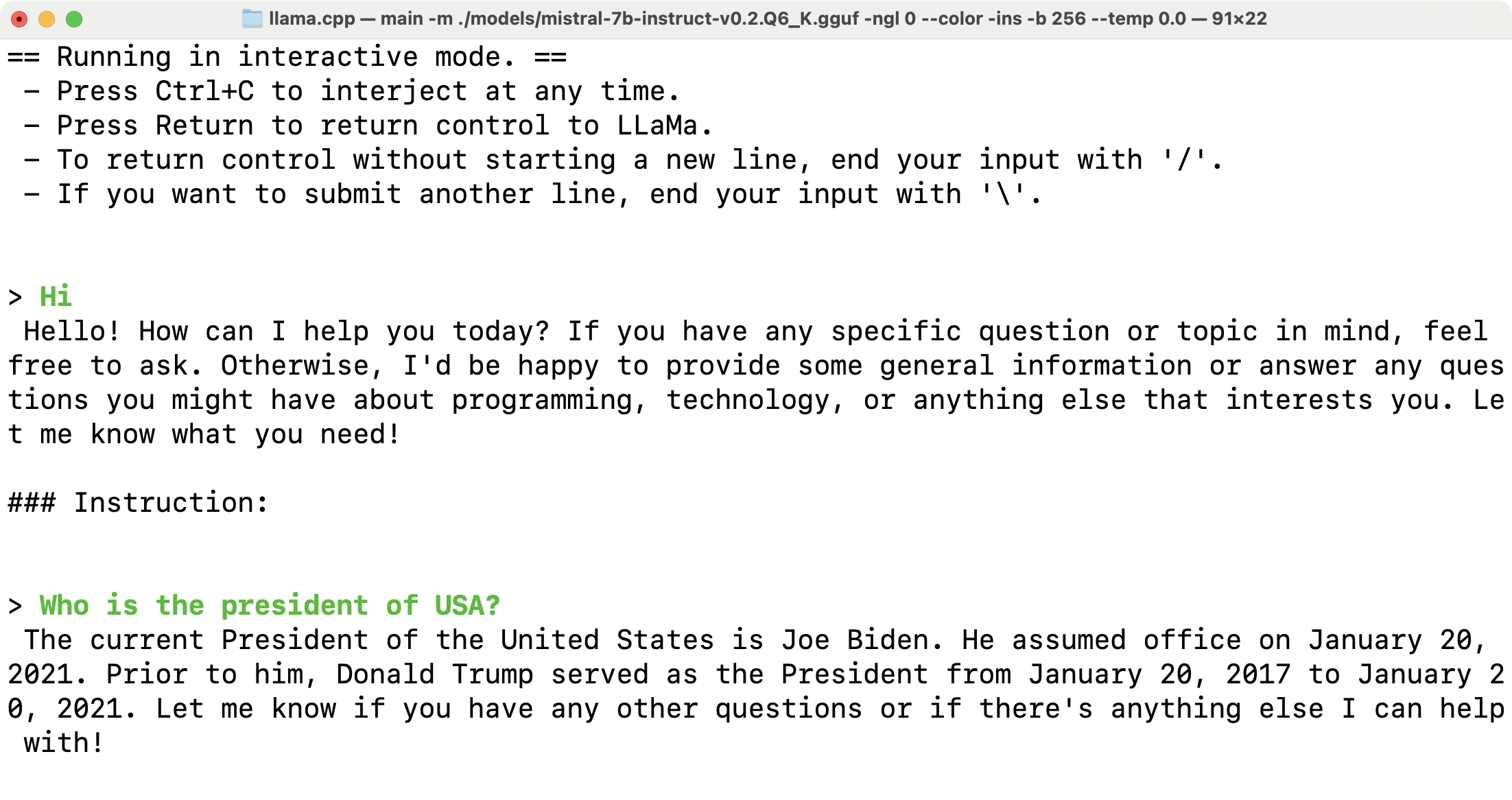
The following command launches the model in an interactive mode.
1
2
3
4
5
./main -m ./models/mistral-7b-instruct-v0.2.Q6_K.gguf \
-ngl 0 \
--color \
-ins -b 256 \
--temp 0.0
The models can be invoked from Python via llama-cpp-python.
1
2
3
4
5
6
7
8
9
10
11
from llama_cpp import Llama
llm = Llama(
model_path="./models/mistral-7b-instruct-v0.2.Q6_K.gguf"
)
output = llm(
"Q: Who is the president of USA? A: ",
max_tokens=32,
stop=["Q:", "\n"],
echo=True
)
print(output)